Have you ever waited for a dashboard to load for so long that you forgot what you were even looking for? I think we all have. It can be incredibly frustrating (especially if your organization is using Redshift…). These days, users expect responsive, low-latency interactions with their data, especially interactive dashboards and exploratory analysis. It’s tricky to deliver on this, even when the data are small, because modern data warehouses are not built for low latency. Instead they prioritizing scalability to work with large amounts of data, and a large number of concurrent queries.
So how do you go about providing an interactive experience on top of a data warehouse? At Cotera, we built the “Split Queries” feature, which aims to do exactly that by using the ERA relational algebra compiler and DuckDB-Wasm.
Splitting Queries Across Data Warehouses
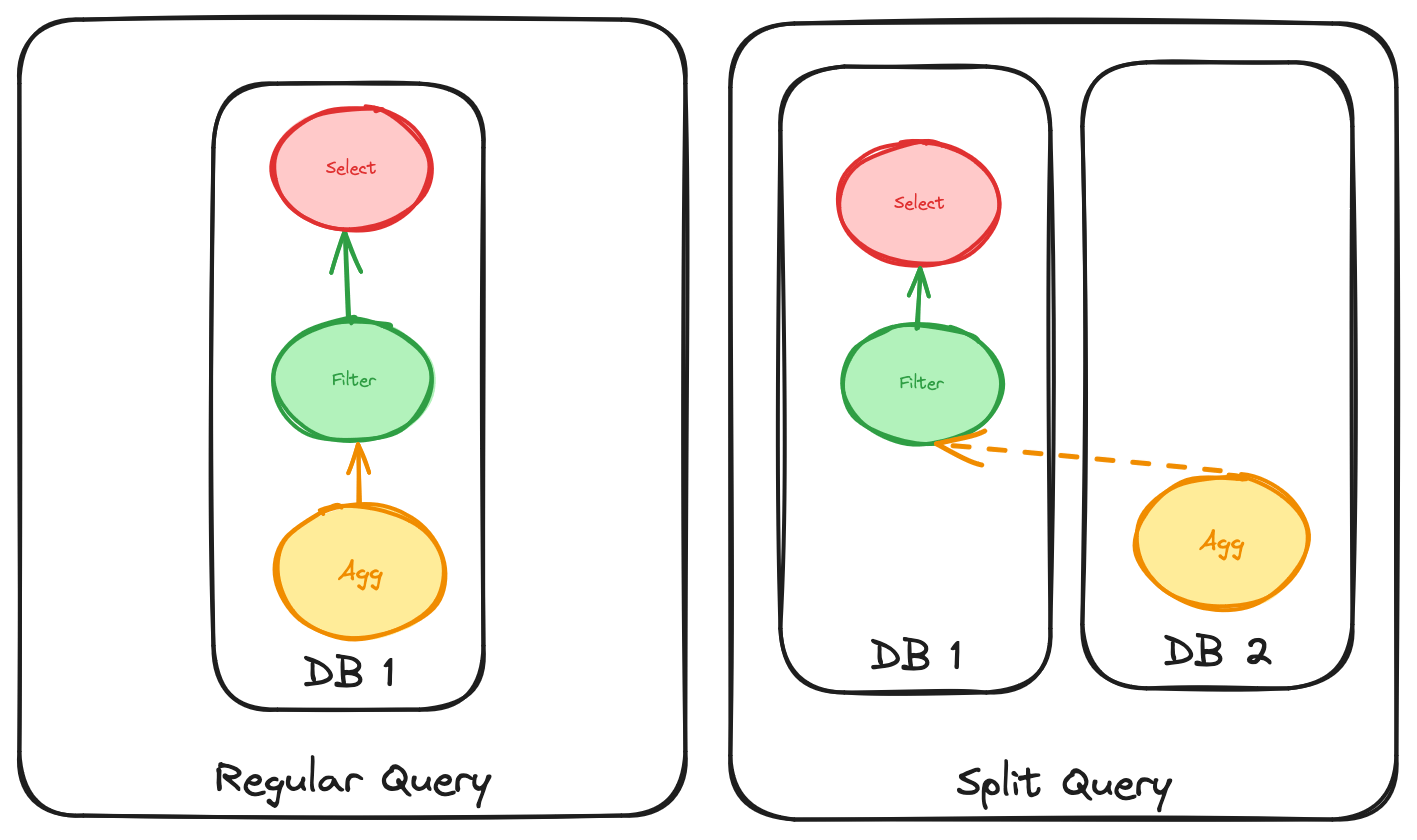
ERA uses the term “split query” for a query that is evaluated across two databases. You begin evaluating the query up to a certain point in one database (usually a primary source of truth data store like MotherDuck or Snowflake) and then you complete the query in another system, like DuckDB WASM running on your laptop or browser.
Why would you want to split a query?
If you’re running a single query, then it doesn’t make sense to do this. However, in practice, queries are rarely one-off. It’s common to ask one question, look at the answer, and immediately think of a follow up.

A common exploratory analytics workflow
The key insight the makes “Split Queries” powerful is that usually follow up queries are extremely similar to the one that came before them. For example, you might start by looking at a metric aggregated by month, then decide you’d like to get a bit more fine grained and query the same metric aggregated by week. Alternatively, you may want to dive deeper and filter by region. The interesting thing here is that these queries can be phrased as a function of the previous query results!

Using ERA Split Queries
Split queries can also make dashboard interactivity much faster using the same technique. As in the example we saw before, follow up questions are likely (or can be engineered) to hit a cache of previous query results, so you spend less time waiting for new results. In Cotera’s commercial product, we use the ERA compiler within our BI tool to do query rewriting from the previous results cache based on user inputs.

Another concrete benefit of split queries is the potential for cost savings. Every time a query hits the cache instead of making the round trip to the warehouse, that's data warehouse compute cost that isn’t being used. What's more, because the cache is shared across the organization, the cost savings scale with the number of users. This means that the cost of running a given dashboard can be significantly reduced, leading to substantial savings over time.
Leveraging DuckDB as an in Browser Data Warehouse
At Cotera, we use DuckDB native/wasm as our Swiss Army Knife for data processing. We use the native DuckDB driver to read and write parquet files to the cache, and use DuckDB WASM in the browser to load parquet files from the cache and do last mile manipulation.
Since the ERA relational algebra compiler can analyze/rewrite queries and ensures the same semantics across multiple targets, we’ve been able to bring last mile DuckDB support to every warehouse via “Split Queries”. since we know we can split at any point and make sure they queries are semantically the same regardless of what part is run where.
How Does ERA do Split Queries?
Understanding “Complete” Query Results
One limitation of any data warehouse client is that it's hard to predict the amount of rows a given query will return. Given the following query it's impossible to infer the amount of rows that it will return.
select * from public.some_table
From({ schema: 'public', name: 'some_table', attributes: { /* ... */ } })
Many clients (including Cotera) will add a fail safe clause:
select * from public.some_table limit 50
From({ /* ... */ }).limit(50)
After running the query we can tell some interesting things. If the above query returns less than 50 rows, we know we have 100% of the data matching that query at this point in time. We call this a "complete" result.

ERA keeps track of any result set that is “complete” and considers it a candidate for reuse in future queries
Knowing how many rows a query will return before running it
In certain situations we can infer an upper bound for rows that a query will produce. The query is broken up into graph nodes like “select” where new columns are generated, a “where” nodes that filters the output, and “limit” nodes that restrict the number of rows. GenerateSeries, Values, and Limit nodes have a defined maximum number of returned rows. The ERA compiler provides an API to getting the maximum possible rows returned from a relation via the .maxPossibleRows method on Relation.

ERA’s analysis of the maximum possible rows a query can return
See here for some code examples
The EraCache engine will always choose to run the query on the earliest possible node in the graph that is guaranteed to be below the fail safe limit. This maximizes possible query result reuse.

ERA chooses to split at the point that has the potential for maximum results reuse
Combining .limit with .invariants
Usually there’s some domain data where you can have reasonably certain upper bounds on the number of rows that will be returned. For example, the Cotera fail safe limit is 100,000 rows, if you were looking at weekly data, this would be almost 2000 years worth of rows.
The ERA compiler provides a easy way to let you share this knowledge with it’s optimizer by using the .assertCachable() method. assertCachable() combines .limit to express to the optimizer that it’s always safe to split a query at this point, and .invariants(more details on how invariants work here) to fail a query at runtime if there were actually more rows in the result set than the fail safe limit, so you don’t have to worry about subtle bugs from truncating result sets on accident
Here’s the ERA source code for assertCachable and assertLimit:

Dealing with JOIN and UNION
Even though the ERA can detect that it’s possible to serve a query from the cache via doing a join or union of two different previous query results, it currently chooses not to.
ERA considers any previous query result as a single point in time, and conservatively won’t attempt to join two different cached results to avoid subtle bugs. For certain types of analyses where data freshness is known, it may make sense to allow ERA to do this type of rewriting. Options to opt-in to this behavior may start appearing in new versions of ERA if there’s desire for them.
Trying it out
The ERA compiler is open source, check it out here. There’s also a learn ERA via examples/koans page here. All of the algorithms to run the cache are provided via the EraCache library that ships with ERA, and we’re working on open sourcing an implementation of an “artifacts” server.
Getting excited for MotherDuck!
Here at Cotera we work with whatever warehouse our customers have, but we’re getting really excited for MotherDuck. We really agree with Jordan Tigani’s takes on how most data fits on your laptop! Give MotherDuck and DuckDB a try if you haven’t already.